Celery AMQP Backends
Note
This started as notes explaining the internals of how Celery’s AMQP backends operate. This isn’t meant to be a comparison or prove one is better or that one is broken. There just seemed to be a lack of documentation about the design and limitations of each backend.
Celery comes with many results backends, two of which use AMQP under the hood: the “AMQP” and “RPC” backends. Both of them publish results as messages into AMQP queues. They’re convenient since you only need one piece of infrastructure to handle both tasks and results (e.g. RabbitMQ). Check the result_backend setting if you’re unsure what you’re using!
AMQP backend
The AMQP backend is deprecated, it uses a results queue per task call, this doesn’t scale well since there is significant overhead (many queues, many bindings, etc.). That’s pretty much all I know about it, I’ve never used it.
A system level view is below:

The caller produces a task into the task queue. The worker consumes the task from this queue and creates a result, which is added to a separate results queue per task call. In the example above there’s tasks A, B, C, etc. Each of those produces a result (A’, B’, C’, etc.) in separate queues.
RPC backend
The RPC backend uses a results queue per client which scales better, but is a bit more limited in functionality — it assumes that the process that produces the task also consumes the result (hence the “RPC” name — referring to remote procedure call). See the announcement of the RPC backend for more information.
A system level view is below:
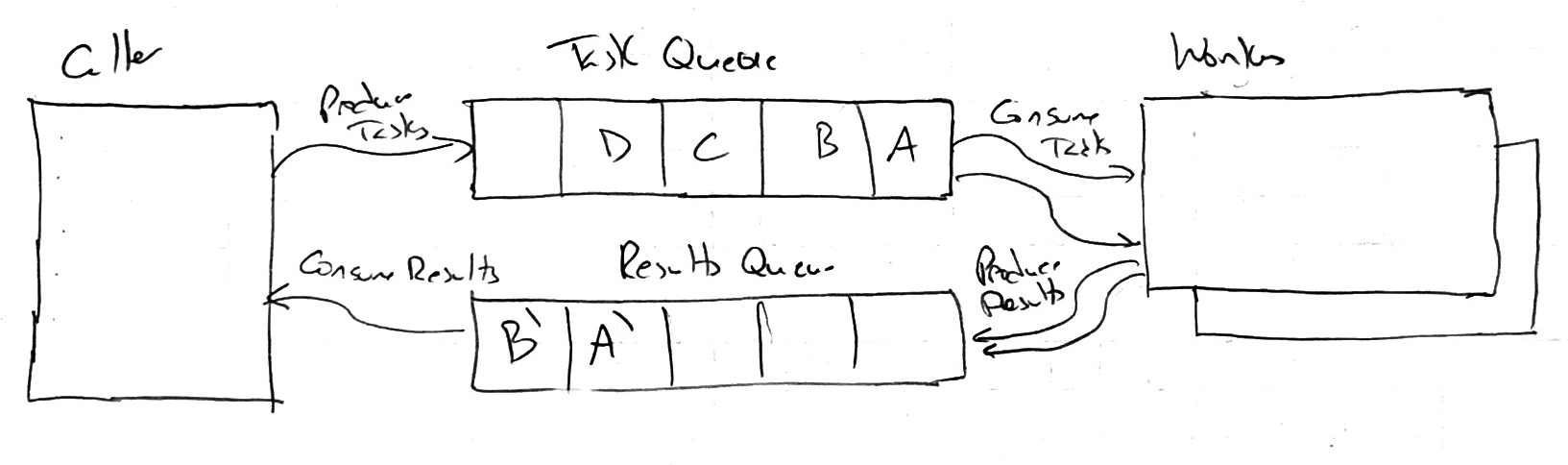
The caller produces a task into the task queue. The worker consumes the task from this queue and creates a result, which is added to a results queue per caller. In the example above there’s tasks A, B, C, etc. Each of those produces a result (A’, B’, C’, etc.) in the same queue.
Since the results go into a queue per caller, this works well when the caller (and only the caller) is what needs to consume the result.
Other things to note with the RPC backend:
- Each result can only be consumed once (since it is then removed from the results queue).
- chords are not supported (but that is not something that I’ve ever used).
- Results are discarded when the client disconnects or if the broker restarts (they’re not durable).
- If there is too much “state history” (if the results queue grows too large), a BacklogLimitExceeded exception will be raised. (By default too large is 1000 pending task results.)
The RPC backend can run into issues with AMQP queues being FIFO — if two tasks (A & B) are started and task B finishes before A, but the client tries to get the result of task A first…what happens? The RPC backend does one of two things:
- Requeues it (the default).
- Caches it locally until it is needed.
The requeuing behavior is shown below:
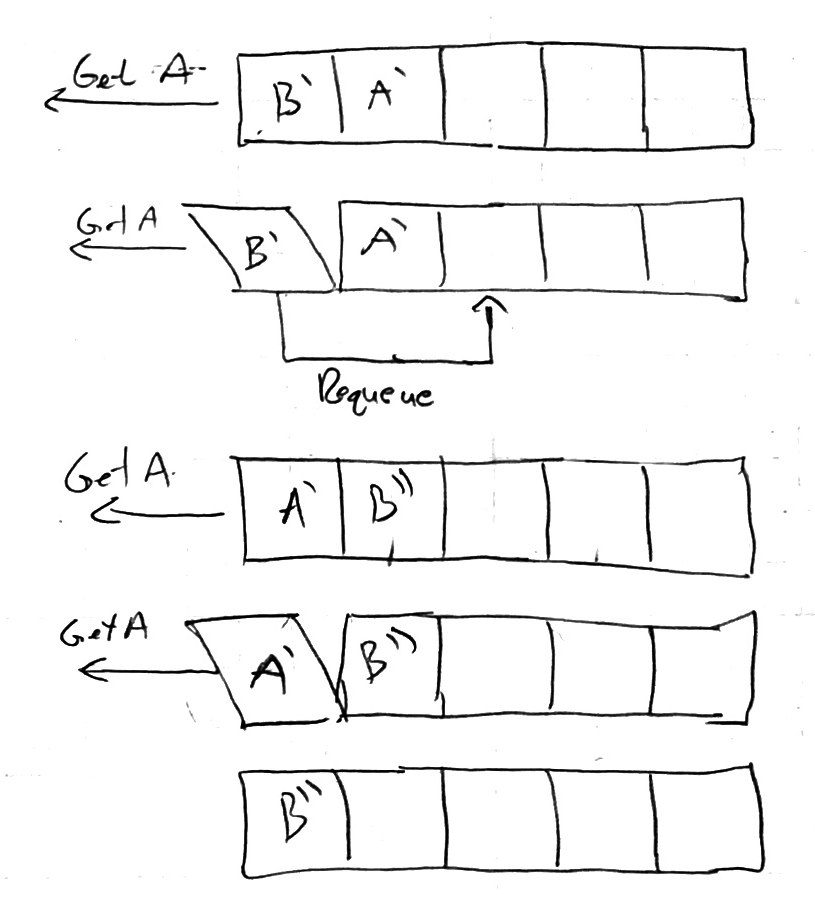
In the example above, result B was added into the queue before A, but A is needed first. The queue is run down until A is received and all other items are requeued (onto the back of the queue).
If you have many parallel tasks running this can cause issues, either by running into the BacklogLimitExceeded error or just lots of churn in the queue (meaning lots of I/O).